Running AI Agents as Background Jobs with Solid Queue
Run AI agents as background jobs with Solid Queue: queue isolation, concurrency limits, safe retries, resumable runs, and per-account cost control.
The first version of an agent job usually looks harmless. A controller creates an AgentRun, enqueues AgentRunJob, and the job calls the model until it has an answer. That is enough for a demo.
The awkward part starts once the agent can do anything useful. It may call the model three or four times. It may run a tool between calls. It may draft an email, update a CRM record, fetch data from an API, or ask a human before doing the last step. Now the job is slow, the retries spend money, and a second attempt is not guaranteed to follow the same path as the first one.
I have written about building the agent itself, with the Anthropic SDK and the Gemini Interactions API. This post is about the part after the demo: how I would run that agent in Solid Queue without letting it block normal jobs, repeat dangerous tool calls, or turn the model bill into something you only understand at the end of the month. It assumes Solid Queue is already running; if not, start with the practical guide.
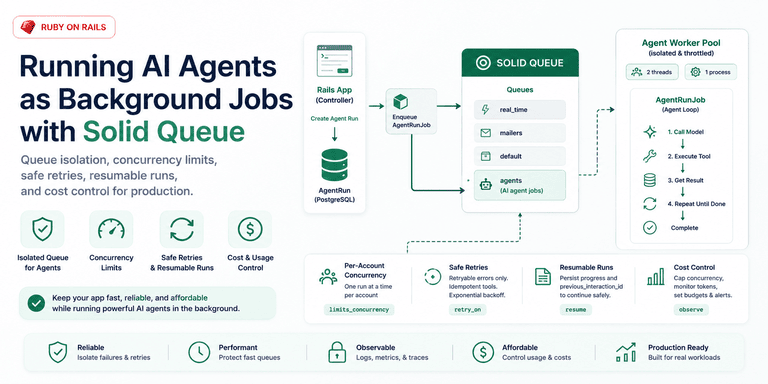
How an agent job differs from a normal job
An agent run breaks three assumptions most queue setups quietly rely on: the job is quick, the job is cheap, and retrying the job is close enough to replaying it. That is mostly true for sending a receipt email. It is not true for an agent that can call tools.
| Property | Typical background job | AI agent run |
|---|---|---|
| Duration | Milliseconds to a few seconds | Tens of seconds across a tool loop |
| Cost per run | Effectively free | Real money, every step is metered tokens |
| Determinism | Same input, same path | Non-deterministic, a retry can take a new path |
| Safe to blind-retry? | Usually yes | No, replays side effects and spend |
| Right home | Shared default queue |
Isolated queue and worker pool |
Read the right column as a list of work you need to do before this belongs in a real app. Queue isolation handles duration. Worker count handles provider pressure and cost. Narrow retries and resumable state handle the fact that an agent cannot be blindly replayed.
Why it has to be a job
I would not put a multi-tool loop in a controller. The request may start with "summarize this account," but the agent might fetch invoices, inspect the last support tickets, call the model again, and then ask whether it should draft a follow-up email. That can easily outlive the web request. The controller should create a row, enqueue the job, and return something the UI can poll or stream against. The job owns the loop.
class AgentRunJob < ApplicationJob
queue_as :agents
def perform(agent_run_id)
agent_run = AgentRun.find(agent_run_id)
agent_run.update!(status: "running", started_at: Time.current)
result = AgentRunner.new(
client: LlmClient.build,
tool_registry: ToolRegistry.new(agent_run.user)
).run(
input: agent_run.input,
resume_state: agent_run.resume_state
)
agent_run.update!(status: "completed", output: result[:output])
end
end
Two small things carry weight here. Marking the run running with a started_at the moment the job picks it up means Mission Control and your own UI show a run in progress instead of a queued job that looks silently stuck. And resume_state is deliberately provider-shaped rather than provider-specific: with the Gemini Interactions API it is a previous_interaction_id the server stores for you, while the Anthropic Messages API is stateless, so it is the persisted message and tool-result transcript you replay on the next call. The queue pattern in the rest of this post is identical either way; only the resume cursor differs, which is why the examples keep it behind one resume_state name.
The loop internals - tool execution, state, parsing - are their own topic, covered in the agent-building posts. The important line here is queue_as :agents. Once the job has its own queue, you can give that workload different workers, different limits, and different retry rules from the rest of the app.
Isolate agent work on its own queue and workers
Start with isolation. A slow job on a shared queue does not only make itself slow; it makes the queue behind it slow. If a 90-second account-research agent lands on default, the password reset, order confirmation, and webhook follow-up behind it all wait for a job they have nothing to do with.
Give agent work a dedicated queue and a dedicated worker pool, separate from the workers that run your fast transactional jobs:
# config/queue.yml
production:
workers:
- queues: [real_time, default, mailers]
threads: 5
polling_interval: 0.1
processes: 2
- queues: [agents]
threads: 2
polling_interval: 1
processes: 1
Now the agent can only occupy a thread in the agent pool. If both agent threads are busy, the next agent waits. Your mailers and transactional jobs keep moving because they are not sharing the same worker threads.
Size the queue database pool for this. Solid Queue recommends keeping worker threads at or below the queue database's connection pool size minus 2, because each worker thread holds a connection and two more are reserved for polling and heartbeat. The two agent threads plus five on the other pool are comfortably inside a default pool, but if you scale the thread counts up, raise the pool first or workers will start failing to check out a connection.
Throttle with worker count, not just concurrency limits
You have two different throttling needs, and they want two different tools.
| Throttling need | Right tool | Example setting | Why this tool |
|---|---|---|---|
| Global rate-limit and cost ceiling | Worker pool size | 2 threads on the agents queue |
Concurrency controls carry per-job overhead when the cap is above 1 |
| Per-account fairness (one run at a time) | limits_concurrency to: 1 |
keyed on account_id |
Cheap at a limit of 1; extra runs wait in blocked_executions |
The first cap is global. It protects the provider API and your budget from a burst of work. The instinct is to express this as limits_concurrency to: 10, but that is not the lever I would start with. If the agents worker has two threads, you have at most two agent runs in flight. No extra semaphore work, no per-job concurrency bookkeeping, just a small worker pool doing exactly what it says.
The second cap is fairness. One account should not be able to click "run analysis" fifty times and fill the whole agent pool. For that I do use limits_concurrency, but with a limit of 1, keyed per account:
class AgentRunJob < ApplicationJob
queue_as :agents
limits_concurrency(
to: 1,
key: ->(agent_run_id) { "agent_run_account_#{AgentRun.find(agent_run_id).account_id}" },
duration: 10.minutes
)
# ...
end
A second run for the same account is held in blocked_executions and promoted when the first one finishes. The duration is easy to misread. It is not "kill this job after ten minutes." It is "if the worker dies and never releases the semaphore, clear the lock after ten minutes." Set it above the longest run you expect. If a run outlives duration, the lock can expire while the job is still working, and a second run for the same account can start.
If duplicate runs should be dropped rather than queued, like a "refresh this summary" button a user can mash, switch the conflict behavior to discard:
limits_concurrency to: 1, key: ->(id) { ... }, duration: 10.minutes, on_conflict: :discard
Use the worker pool for the global ceiling. Use limits_concurrency for the per-account rule. They solve different problems.
Retries cost money and do not replay
This line looks reasonable until the job can call tools:
retry_on StandardError, attempts: 5
For a normal job, broad retry rules can be fine. For an agent, they are a liability. Imagine attempt one sends a customer email through a tool and then times out while writing the final response. Attempt two does not "continue" the first attempt unless you built it that way. It may spend the tokens again, call the tool again, and produce a different final answer.
I keep the retry list boring and narrow. Timeouts and rate limits get another attempt. Bad input and missing records do not. A malformed request will not become valid because Solid Queue tried it four more times:
class AgentRunJob < ApplicationJob
queue_as :agents
retry_on Faraday::TimeoutError, wait: :polynomially_longer, attempts: 3
retry_on ProviderRateLimited, wait: :polynomially_longer, attempts: 5
discard_on AgentRun::InvalidInput
discard_on ActiveRecord::RecordNotFound
# ...
end
The other half is state. Persist the provider resume state, the tool calls that already finished, and enough output to know what happened before the failure. A retry should continue the run, not re-charge the card or send the same email again. The provider's 429 should trigger backoff, but the real throttle is still the worker count from earlier. This is the same at-least-once delivery model that makes recurring and cron jobs in Solid Queue need idempotent bodies; an agent just makes the mistake more expensive.
Deploys will interrupt long runs
Long jobs meet deploys eventually. When Solid Queue shuts a worker down, in-flight jobs get a grace period before they are terminated. Solid Queue's own shutdown_timeout defaults to 5 seconds; your deploy tool usually stacks a longer container stop window on top of that - Kamal 2's drain_timeout defaults to 30 seconds, and Kubernetes commonly gives 30 seconds too. Either way, a two-minute agent run is not going to politely finish before the QUIT arrives just because you are deploying.
You can raise shutdown_timeout, but I would not make deploy speed depend on the longest possible agent run. The better fix is the same state you needed for retries. Persist the resume state and completed steps as the run progresses. If a deploy interrupts the job, re-enqueue it, pass the stored resume_state, and continue instead of starting from an empty prompt.
Human-in-the-loop without holding a thread hostage
Agents that can write should pause before doing irreversible work. Draft the refund, email, subscription change, or database update. Let a human confirm it. Then execute. The queue question is what happens during the pause.
The tempting implementation is a sleeping job that polls for confirmation. That burns one of the few agent threads while the user is reading, taking a call, or leaving the tab open during lunch. It also dies on the next deploy.
End the job instead. When the agent reaches a step that needs confirmation, persist the proposed action and the resume state, move the run to waiting_for_confirmation, and return. The worker is free again. The database row is the pause.
def perform(agent_run_id)
agent_run = AgentRun.find(agent_run_id)
result = AgentRunner.new(...).run(
input: agent_run.input,
resume_state: agent_run.resume_state
)
if result[:needs_confirmation]
agent_run.update!(
status: "waiting_for_confirmation",
resume_state: result[:resume_state],
pending_action: result[:pending_action]
)
return
end
agent_run.update!(status: "completed", output: result[:output])
end
When the user confirms in the UI, the controller enqueues a continuation that resumes from the stored state:
class ResumeAgentRunJob < ApplicationJob
queue_as :agents
def perform(agent_run_id)
agent_run = AgentRun.find(agent_run_id)
return unless agent_run.status == "waiting_for_confirmation"
result = AgentRunner.new(...).run(
input: "User confirmed the pending action.",
resume_state: agent_run.resume_state
)
agent_run.update!(status: "completed", output: result[:output])
end
end
The pause now costs zero worker time and survives deploys because there is no running job to kill. There is only a row waiting for a human decision.
Persist runs and track cost
Write the run record yourself, even if the provider has a dashboard. The provider can tell you tokens were spent. It usually cannot tell you that account 184 spent them while running the "prepare renewal notes" agent from the admin screen.
I want three things in my own database: the run, the steps, and the usage. The run tells me who asked for what. The steps tell me which model calls and tools happened. The usage tells me what it cost. Mission Control Jobs gives you the queue-level view of failures and retries, but the per-step trace has to come from your app.
When you do not need any of this
If your "agent" is a single model call - classify this ticket, extract three fields, rewrite a title - skip most of this. Put it on a normal job, retry it like any other API call, and move on. The isolated queue, resumable run state, confirmation pause, and cost ledger are for loops that call tools or spend enough money to matter.
One sharp edge before you lean hard on concurrency limits: under large spikes, Solid Queue can be slow to promote blocked executions back to ready. That is acceptable for per-account fairness on long agent runs. I would not put it on a path where a few seconds of promotion delay matters. If you are weighing the backend itself for this kind of workload, the Solid Queue vs Sidekiq vs GoodJob comparison covers where each one earns its keep.
The agent loop is the visible part. The queue setup is what decides whether you can live with it after users start clicking the button. Most of it degrades politely when you get it wrong: an undersized worker pool just queues work, a loose retry rule wastes some tokens. The piece that does not is replayed side effects - a retry that repeats a finished tool call sends that customer email twice, and no queue setting saves you from it - so if you build only one thing from this post, build the resumable run state. If you want a second read on which of your jobs have that problem, send me your retry_on rules, your limits_concurrency blocks, and the job bodies they wrap. I will flag the ones that are not safe to replay, before a retry does it in front of a customer.